5 mistakes that result in duplicate content

If you are of the kind that copies and pastes third-party content-or your own-at will on a lot of pages of your site, hoping vaguely that you escalate positions in search engines, then you need not read this post: you know perfectly well why you have duplicate content.
But if that is not your case and you want to know some of the possible reasons why Google thinks you have duplicated content, even though you do not, then keep on reading.
1.- Same content, different format, different URL
This is one of the most common cases.
Many times our web has several versions adapted to the different devices, and even a “print view” that generates independent pages with their own URL.
In situations like these we have to state that there is a home page and that the rest are just iterations presented in a different way. What we have to do is use the tag “canonical” to indicate which is the main page and what are its “copies”.
Suppose we have the URL “http://www.example.com/example” and a printed version like “http://www.example.com/print/example”. In such a case, we should specify that the second URL is a version of the first-and not duplicated content-using the tag:
<rel=”canonical” link href=”http://www.example.com/example” />

2.- “www.” o not “www.”, that is the question
If you do not state it otherwise, Google will understand that a web page whose domain can be with or without the “www.” is not the same, but two different websites with identical content.
In a practical sense, we do not care whether we access “example.com” or “www.example.com”, because I will see the exact same thing on my screen. But if the site’s administrator has not specified on Webmaster Tools which of the two is the favourite version, there can be trouble.
It is also recommendable to set up 301-redirect directives for all the URL that take to the same page, the favourite one.
3.- The only solution is having a lot of very similar pages
Sometimes the nature of our website forces us to have several pages which are almost identical.
So if we do not want this to be a lag for our SEO ranking, we must make clear to the web searchers not to take into account all these contents which are almost identical to each other. We have to have the robots prepared so that when they scan the sites they know that these pages must not be indexed. For this, it is enough to include the following code under the heads:
<meta name=”robots” content=”noindex,follow”/>
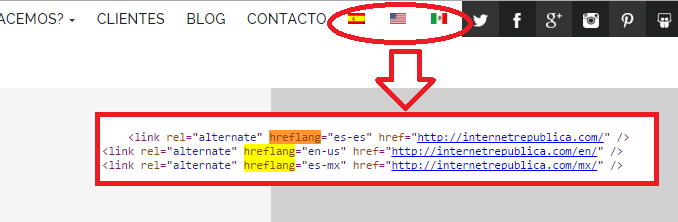
4.- Multilingual webs
If our web has a version in one or more different languages, we have to include this information. Failing to include this will result in the searches thinking they are duplicated content.
How do we do this? With the tag HREFLANG.
This tag has to be present in each and every page of the website and it must specify each and every language in which our information will be displayed.
You can learn in more detail how to configure the tag HREFLANG in this other post from our blog.
5.- Some heartless fellow is copying your content
That you are not copying and pasting third parties content from anywhere to include them in the pages of your website, hoping in vain that your site will be better ranked in search engines, does not mean that everybody behaves as honestly as you do.
This can become a big problem, especially if the person taking advantage of your work has an older website with higher notoriety than yours, which makes it more trustworthy for search engines.
It is important to track our contents and protect them from plagiarism. There are tools for this like Plagspotter, Copyscape or Copygator than can come in very handy.

As you can see, there are many ways in which duplicated content-or apparently duplicated-can be generated without our noticing. These are just some very common examples than can in general be solved relatively easily. Have you already checked that your website does not have these problems?



Internet República
Latest posts by Internet República (see all)
- New Instagram update: reel achievements - 19 October, 2023
- Elon Musk has bought Twitter. What does this mean? - 27 April, 2022
- NFTs ARE ARRIVING ON SOCIAL MEDIA - 21 February, 2022
