
Analyse your duplicate content with Safecont
As we already know, content is one of the main pillars of SEO. Your website needs to have good content to improve your web positioning. We must not forget that content must provide value to the user and that Google penalises duplicate content. It is essential to highlight that Google considers duplicate content when the pages are similar or almost identical, although they have different URLs. These URLs can be within the same domain, i.e., duplicate content internally within your site or others which could be the external duplicate content.
For this analysis, I would like to show you Safecont which, in the words of its creators, is the most advanced tool for SEO analysis and content quality.
Safecont gives an estimate of the chance that your domain will be penalised by the search engines.
How does Safecont work?
The system is easy to use. Enter your domain and launch the analysis. You can also configure some parameters to perform slow indexing or deny crawling certain parts of the web that do not interest you. Then you wait for the Safecont crawler to analyse the site so you can see the analysis it generates.
Safecont Report “Home Page”
When you click on view analysis, the first screen shows you a summary as you can see in the following image:
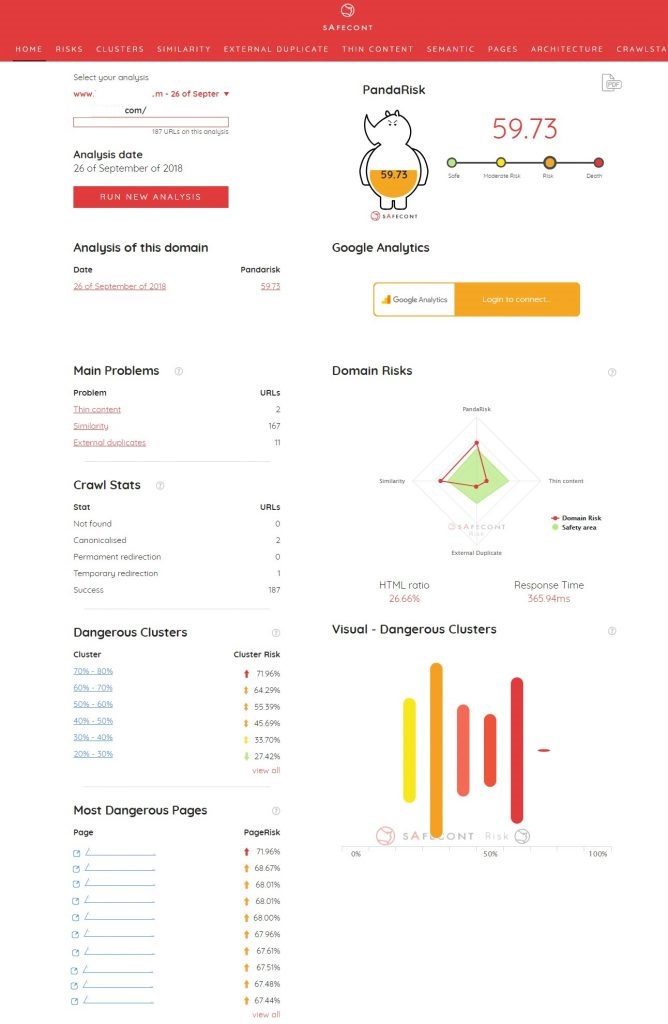
First thing you see is the score that Safecont considers whether your domain can be penalised by search engines, which they call PandaRisk. They explain it as “Score that Safecont gives to a page/URL within the analysed website according to the risk it runs of being algorithmically penalised by search engines. The score ranges from 0 % to 100 %, the closer to 100 the more likely it is to be penalised. Low danger values are shown in green, intermediate values – in yellow and orange, and the most dangerous ones – in red. PageRisk is calculated based on multiple factors including internal similarity, possible thin content problems, external duplication, etc.”.
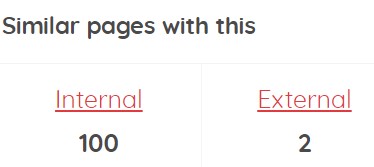
Then, it shows you the number of pages with a thin content problem (pages that have little content), similarity or external duplicate content (if you have configured this in the launch of the analysis). If you click on each one, you will be taken to the detailed information of the pages with these problems (you can also access any information on the main screen, from the top menu). For each of these problems, it will show you the information segmented by percentages, so that you can prioritise the information and at the end, it shows you the total list. Once there, click on the red circle with a “+” to see the detailed information for each page. Within this information, it is important to go to the information in the following image, where you can see which pages are similar internally on the site, as well as their percentage of similarity and the external similar pages and their percentage.
Next, it shows the information by clusters, grouping the pages, 10 by 10, that have the three problems, as well as the risk they represent. The operation is the same, click on each one, and analyse the different pages by clicking on the red circle with a “+”.
And finally, it shows you the most dangerous pages.
As mentioned above, each of these sections on the main page can also be accessed from the top menu under Risks, Clusters, Similarity and External Duplicate.
From the “Pages” tab in the top menu, you can access all the pages analysed, as well as the problems presented by each one, i.e., we have a complete list of all the pages.
Finally, it is interesting to analyse the “Architecture Analysis” tab, where you will obtain an analysis of the information architecture of the analysed website, with the classification by levels of depth, a graph with the authority of the site’s interlinking, the most powerful pages, and the most popular anchor texts.
Conclusion
In my opinion, it is a tool that gives a lot of valuable information, but you must analyse it well, as common elements that you have on your page, such as the footer, sidebars, etc., will give you similarity problems, so if these contents are very extensive, the percentages can be remarkably high. It does not necessarily mean that the real content of the page is duplicated; neither it considers whether you already have a canonical tag on the pages that you have detected as duplicates, so you must filter that information.



Erica Del Amo
Latest posts by Erica Del Amo (see all)
- Analyse your duplicate content with Safecont - 5 October, 2018
