Extracting customized content with regular expressions on Screaming Frog
One of the latest improvements of Screaming Frog is that it allows extracting HTML code under customized fields with regular expressions.
These customized fields can be exported to Excel with the other common parameters of crawling (title, h1, canonical, etc.).
With the power of regular expressions and our imagination, we can use those customized extraction fields to obtain relevant information for our crawling.
We have to warn that the Screaming Frog tool has to be used responsibly, and only to crawl your own sites or those you have a permission to crawl. If there are many simultaneous requests for small sites without a good hosting infrastructure, the server may collapse.
Which authors from a blog generate more visits?
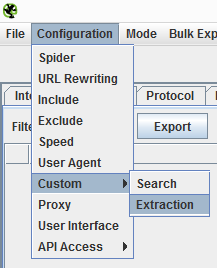
We create a customized extraction filter taking into account the HTML with the name of the author. This could be something like:
<div class="autor"><h3 class="nombre_autor" ><a href="/john-doe” class="url">John Doe</a></h3>
<div class="autor"><h3 class="nombre_autor" ><a href="/juan-nadie” class="url">Juan Nadie</a></h3>
The regular expression to capture the name would be similar to:
<div class="autor"><h3 class="nombre_autor" ><a href=".+" class="url">(.+)</a></h3>
Note: These regular expressions are for guiding purposes only. There are a lot of tutorials to learn how to use them.
Additionally, if we use Screaming Frog for crawling applying the functionality to link to Google Analytics, we will extract all the usual fields as well as that of author and the sessions of organic traffic.
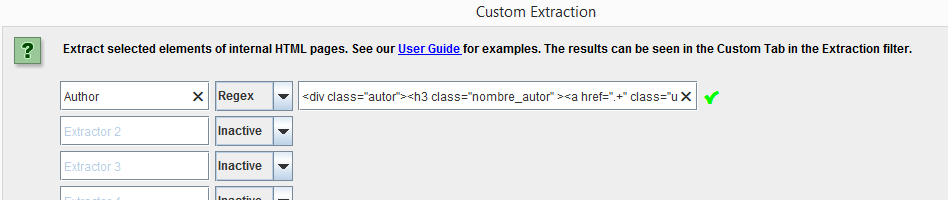
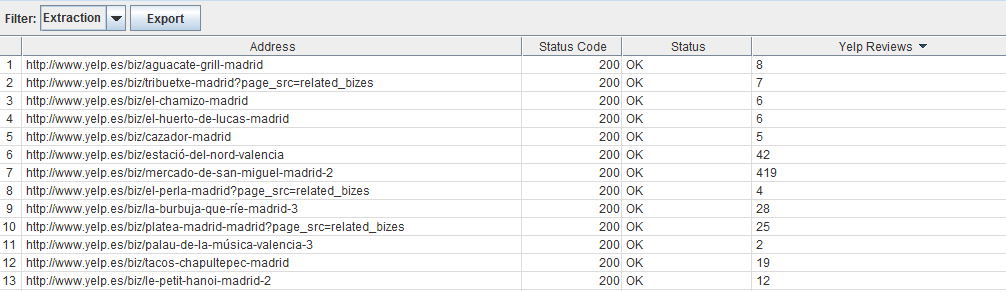
With this we will obtain a list with the most visited URLs and the author of each of them.
Here you have a real example:

How many comments or reviews does a product have?
Screaming Frog does not capture the code generated on JavaScript by modifying the DOM, it only captures the content present in the source code.
Therefore, you have to make sure that the number of comments is shown in the HTML. Do not use the option “inspect element” but “see source code.”
We can for example obtain the number of reviews of restaurants.
We would also like to tell you that regular expressions are greedy by nature, so they will try to take up as much as possible of a code chunk meeting the indicated pattern. This is why you have to use expressions in the patterns capture where you limit the type of characters.
To try a regular expression you can use this tool.
Paste the HTML code of the page you want to extract and try out if it is capturing well to use this expression with Screaming.
Traces as HTML comments
Screaming Frog can capture any part of the HTML code of a webpage, so we can use this to extract comments or traces included in the pages. The comments on HTML format are not displayed in the user’s page, and the robots do not read them, so you need not hide them.
We can for example create a comment with the time that a request takes to execute on BD and then analyse the slowest URLs. For this we only have to generate an HTML trace of the kind <!-- Consulta: 0.982 ms --> with the programming language we use. This will be captured in a customized extraction field.
And for those that do not want to add relevant data, they can alter the real value using a K multiplier to distort the time shown, so that even if the source code says that it took 0.982 ms, the real time will be 0.982 / K
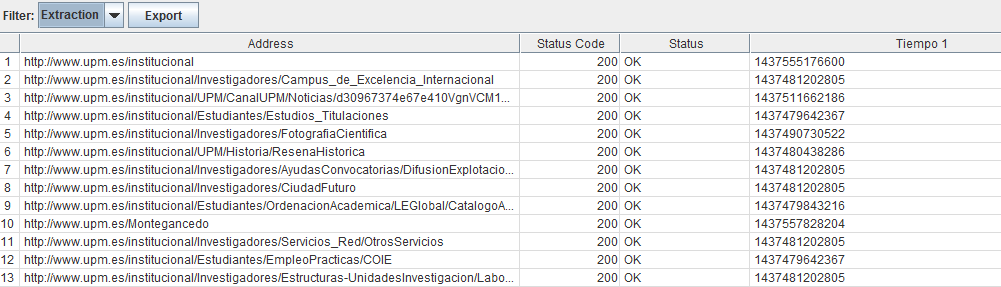
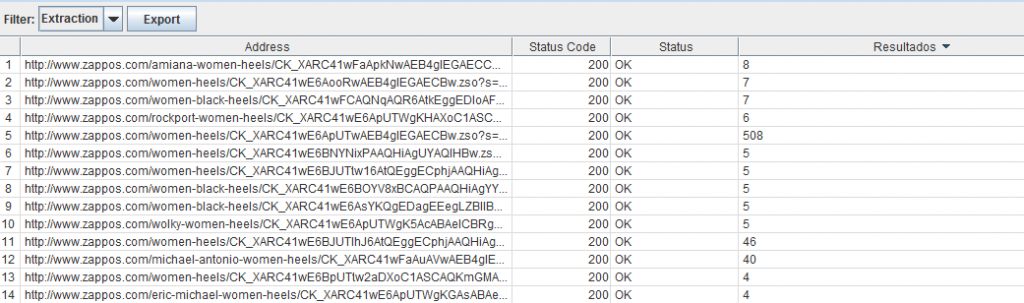
Number of results in the search pages
The search results pages are very useful for SEO, but there always have to be a precaution not to index pages that give no results or very few results. There is a risk that a different search might deliver the same result.
We can create a regular expression that extracts the number of results of a search page to see which are linked to the website and have no results.
And many more…
These were just a few examples, but this option gives way to many more possibilities.



Internet República
Latest posts by Internet República (see all)
- New Instagram update: reel achievements - 19 October, 2023
- Elon Musk has bought Twitter. What does this mean? - 27 April, 2022
- NFTs ARE ARRIVING ON SOCIAL MEDIA - 21 February, 2022
