The Google Wall: Javascript experiments 2020
Hello, community!
I recently participated in ClickSEO 2020 as Internet República’s SEO Manager, a free online event that took place on the 7th and 8th of December with the participation of many SEO experts, and in which also participated my colleague Marta Romera, Internet República’s SEO Manager.
My speech at ClickSEO was about some experiments we have done with SEO and JavaScript in 2020, which I want to tell you about here.
Even though I will explain what these experiments were in this article, you can see the full presentation here.
Google announced Google Evergreen in mid-2019, and we wanted to do some JavaScript experiments to see how it was different from others we did in 2019, and whether there have been any changes.
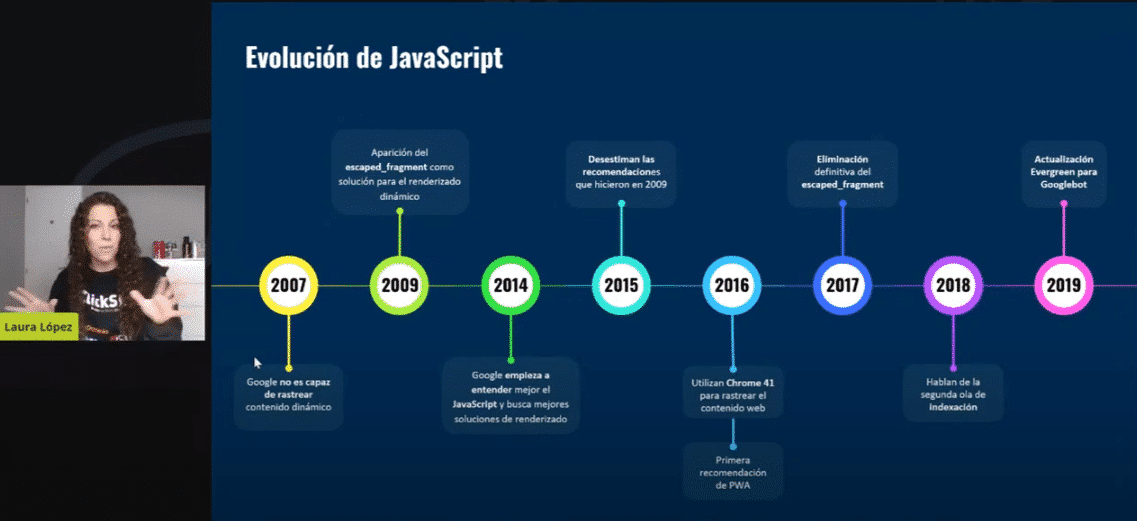
As you know, SEO in JavaScript has had a quite remarkable evolution during the last few years. Think that Google was not able to process pages in JavaScript back in 2009 what they announced and recommended that we should include an element in the URL called “escaped fragment” so that they could understand which pages had a dynamic content change for the possibility to identify and process them. Google was not capable of interpreting when a page changed dynamically, as it could not process JavaScript.
At the annual conference in 2018, they already announced how they were processing JavaScript, but it was not until 2019 that Google started using Evergreen, the latest Chrome version to process and render this content in JavaScript. It was going to be a real breakthrough; Google was going to progress and improve a lot. Now we will see if this is the case.
Everyone wants the new pages to be made in JavaScript to improve the users’ experience and make the content more dynamic. When a new client comes to a big agency like Internet República, we ask what technology the website will be developed in and the changes they want to see.
The development of web pages using this type of technology is growing drastically. Yet not everything seems to be that pretty, or that functional.
What problems do we face with SEO and JavaScript?
The main problem is the process that Google follows to crawl the content, which is that Googlebot downloads the HTML file, say the basic part, and from there it finds JavaScript (the content in JavaScript, its CSS functionalities, etc.). This is where Googlebot identifies and processes that content. Processing that HTML page with these CSS JavaScript resources, checking them, compiling them, and executing them. Those contents are then passed to the Google renderer and indexed by Google.
This compilation and execution of the JavaScript take much longer than processing a page in traditional HTML. Therefore, we are already going to have an issue with the time it takes to process our pages with JavaScript content.
Google indexes what it renders, i.e., if there is a part that it has not had time to render or that it has not rendered at all, it will not be indexed. Thus, it is particularly important to make sure that Google renders what we have in JavaScript and fully indexes it. When crawling JavaScript content, those links are supposed to be processed, executed, and indexed, but there are times when this does not happen, and some links are left unprocessed.
Besides, there is the problem of a limited crawl budget on normal pages, which means that all the time it takes to process the page also affects our ability to work with other pages in JavaScript.
How is it being done now, or how does Google claim to be doing it when they announce this change to Evergreen? What does it mean when they announce processing of JavaScript with the latest version of Chrome?
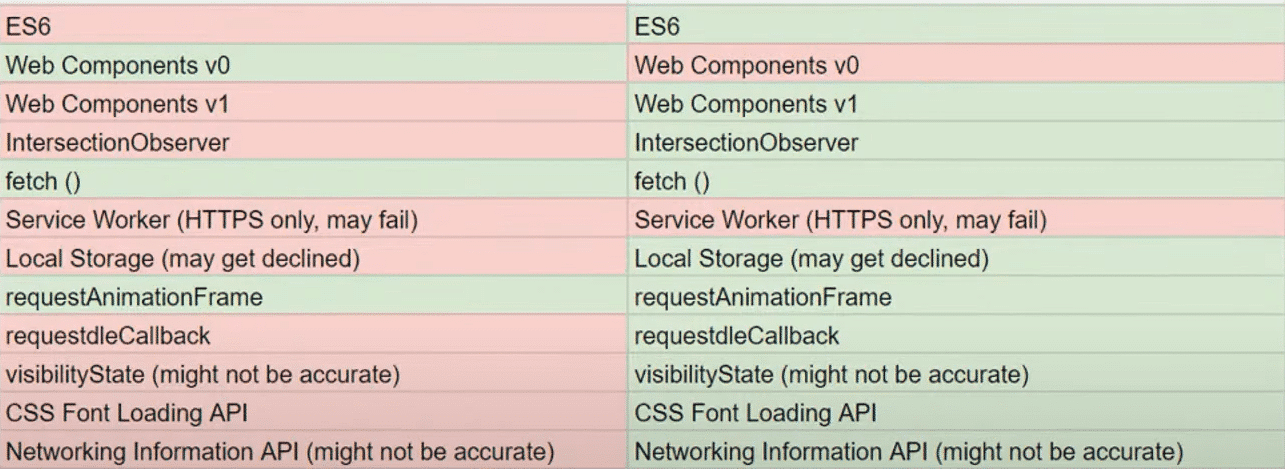
The table below shows some of the JavaScript features (in red) that they were not able to process in the past, and that is now possible wit with Evergreen. If you have a page with a lot of JavaScript code in which you had features like the ones marked in red that Google could not process before, your content will be processed better now.
What experiments have we done?
With the experiments, we wanted to see if this makes any difference. We are going to show how the user sees the content of a web page in JavaScript and how Google sees it. And the main differences are:
- Googlebot does not download all the resources that exist on a page. Therefore, a user enters a page in JavaScript and sees all the content, although there are times when Google does not process all those resources and some of the content may not be seen. Given all the personalisation that we see on websites and the JavaScript technologies that make dynamic content, we must bear in mind that this is invisible to Google since it does not use cookies.
- Google only renders 5 seconds that we are going to check in the tests, although I wanted to check if with Evergreen in 2020 something has really changed or whether we still have those 5 seconds rendering time.
- Another thing that is known and proven is that Google does not interact with certain resources, but we wanted to check this as well.
The experiments we did in 2019
We defined a series of tests during 2019 before Evergreen, so that you can see the difference with what we had in 2020.
The first thing we did in 2019 was to generate a page with a scrolling product that loads directly when you enter the page, but products 2, 3, and all the rest load only when you scroll. So, we said: “let’s see if Google can index the content of products 2 and 3. Product 1, which does not have a scroll option but is directly displayed on the page, is indexed perfectly, but in 2019 Google wasn’t able to scroll and did not index the content I had set up under a JavaScript scroll.
The second test we did was to set up a page with a “load more” button in JavaScript. Many e-commerce pages have a “see more” button with a JavaScript event, and when you interact with the button, it loads the rest of the content. We tested it and found that Google does not interact with this JavaScript button or, at least, it did not when we ran the tests in 2019.
The third test we did was a sequential loading – loading parts of the code every second to check how long Google took to index this part of the code so that it could give us a snapshot of the maximum time Google took to index the page. We confirmed that it was 5 seconds for Google to process and index this content.
We also captured cookies to see if it had them enabled, and yes it did, but they do not remain persistent between requests. In other words, you cannot use the content with cookies.
What changed in 2020?
In 2020 we wanted to check if anything changed with Evergreen. What we did was the same, check if under the scroll we indexed the content. The result is that product 1 does load, but if we scroll down, Google does not catch anything.
We also wanted to check if Evergreen, with the new features, captures the interaction on JavaScript buttons. Indeed, just like last year, it does not engage with those buttons.
Finally, we wanted to check if Evergreen had improved the 5 seconds rendering time, we had last year. And as we have seen in Google Evergreen, the rendering is still 5 seconds for practical purposes. We must ensure that our JavaScript page loads correctly in 5 seconds.
To sum up, both 2019 and 2020 experiments are the same. All the tests we have done have been the same, except for the different versions of Chrome, which is more up to date in 2020.
It still does not detect the scroll and does not load the “see more” button, the rendering and indexing takes 5 seconds, and the cookies are enabled but do not remain active between requests.
To conclude, it is all the same in 2020 as it was in 2019. In my opinion, Evergreen has not changed at all, the indexing continues to work the same way, and we will have to keep doing the same SEO for JavaScript as we have bee



Laura López
Latest posts by Laura López (see all)
- The Google Wall: Javascript experiments 2020 - 12 January, 2021
- Internet República on SEonthebeach 2016 - 19 July, 2016
